Seedance 1.5 Pro: Redefining Audio-Visual AI Generation

I've tested enough AI video tools to know the pattern: impressive visuals paired with audio that feels tacked on afterwards. The lip-sync is off, the environmental sounds don't match, the music feels generic. ByteDance's Seedance 1.5 Pro breaks this mold entirely. This tool generates audio and video as inseparable twins—not as separate tracks forced together, but as a unified creative output from the start.
The Bold Leap from Stability to Spectacle
ByteDance's latest release, Seedance 1.5 Pro, marks a departure from the cautious approach of its predecessor. While version 1.0 prioritized motion stability and glitch-free output, the 1.5 Pro iteration embraces ambition—targeting that elusive "wow" factor in both visual and auditory dimensions.
This isn't your typical video generator that treats audio as an afterthought, slapping generic background music onto clips. Seedance 1.5 Pro creates audio and video as inseparable twins, handling everything from text-to-audio-video synthesis to image-guided generation with a level of integration I haven't seen elsewhere.
Why Audio-Visual Sync Actually Matters Now
After testing numerous AI video tools, the difference is striking. Most platforms handle audio separately, resulting in that disconnected feeling we've all experienced. Seedance 1.5 Pro breaks this pattern with precision lip-sync—when characters speak, their mouth movements genuinely match the dialogue.
The multi-language capabilities extend beyond simple translation. The model captures regional dialects with their unique rhythms and emotional nuances, supporting Chinese, English, Japanese, Korean, Spanish, Indonesian, and even Chinese dialects like Sichuanese and Cantonese. Imagine a realistic panda munching bamboo, then breaking into Sichuan dialect complaints with perfectly matched expressions and timing—it delivers exactly that kind of authentic, hilarious result.
Technical Architecture: What Powers This Thing
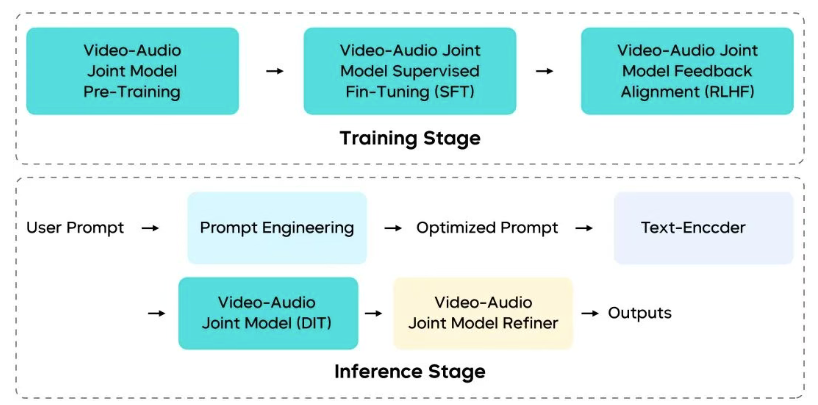
The foundation rests on a joint audio-video generation model with several key innovations:
Multimodal Joint Architecture: Built on MMDiT architecture with a unified audio-video generation framework. Deep cross-modal information interaction mechanisms ensure precise coordination between visual and auditory streams in both temporal synchronization and semantic consistency.
Multi-Stage Data Pipeline: Balances audio-video consistency, motion expressiveness, and curriculum scheduling. This significantly enhanced video description richness and professionalism while incorporating audio descriptions for high-fidelity generation.
Refined Post-Training: High-quality datasets feed supervised fine-tuning (SFT), combined with RLHF algorithms customized for audio-video scenarios. Multi-dimensional reward models enhance T2V and I2V task performance across motion quality, visual aesthetics, and audio fidelity.
Efficient Inference: An optimized multi-stage distillation framework dramatically reduces function evaluations (NFE) needed for generation. Quantization, parallelization, and infrastructure optimizations deliver over 10x end-to-end inference acceleration without sacrificing performance.
Cinematic Capabilities That Stand Out
Camera Movement That Understands Drama
The cinematography impressed me most. Long tracking shots, Hitchcock zooms—techniques that typically require skilled cinematographers—emerge naturally from the model. It's not random application either; the system understands when these techniques create dramatic effect.
In extreme sports scenarios like skiing, rapid camera movement syncs with audio cues for intense presence. Low-angle long takes follow carving turns, capturing snow spray in meticulous detail, paired with rushing wind and energetic Future Bass tracks.
Even product advertisements benefit. A robotic vacuum promo uses slow, deliberate pushes and tracking to highlight the device in a minimalist luxury home, accompanied by smooth AI voiceover.
Narrative Structure Beyond Isolated Clips
Seedance 1.5 Pro treats video and audio as one unified whole, understanding story context rather than just generating pretty clips. The audio-video segments flow with actual narrative coherence—crucial for professional content in film production, short dramas, advertising, and traditional opera performances.
The upgraded semantic understanding interprets subtle human emotions and translates them into compelling visuals. In a cyberpunk-style scene, it infers backstory from the prompt, rendering a young East Asian woman's emotional shift from suppressed sadness (tears welling up) to quiet determination as sunrise light hits her face—complete with film-grain texture and shallow depth of field.
For an anime-style fireworks festival confession, it sequences shots with narrative structure: wide shots of exploding fireworks, pushing in on the couple in traditional attire, capturing emotional buildup with Japanese dialogue and ambient crowd noise for seamless romantic flow.
Environmental Audio That Creates Spatial Depth
Beyond speech generation, the model layers ambient audio based on visual content—what you see is what you hear.
In pixel-art game segments, camera tracking follows character running and jumping fluidly while generating matching 8-bit sound effects. A 3D game-style clip set in abandoned church ruins synchronizes footsteps, heartbeats, and owl calls precisely with character movements, building suspense with tense background music.
Performance Against Industry Benchmarks
The Testing Framework
The team built SeedVideoBench 1.5 with film directors and technical experts to objectively evaluate the model. It tests complex instruction following, motion stability, aesthetic quality, audio instruction following, audio-video sync, and audio expressiveness.
Video Generation Results
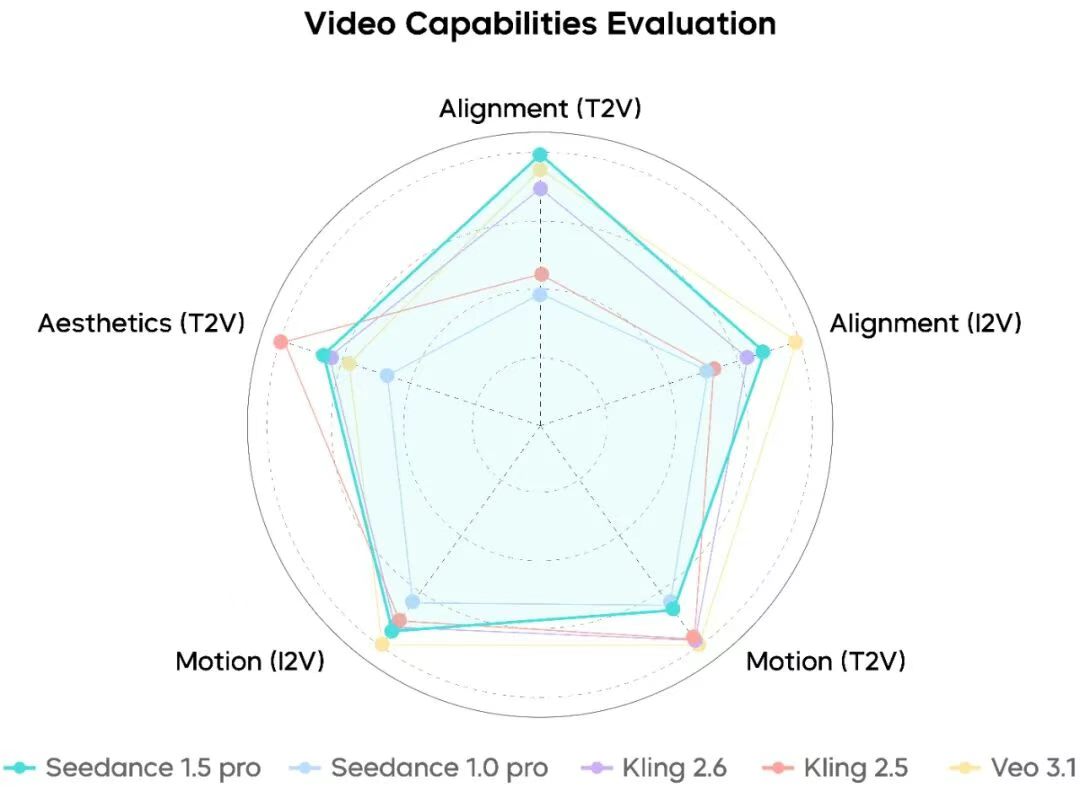
Compared to competitors, Seedance 1.5 Pro demonstrates superior understanding of complex instructions about actions and camera movements. It matches narrative and cinematic styles specified in prompts more accurately than most alternatives.
Dynamic performance feels full and alive—character facial expressions in close-ups are vivid, complex camera movements flow relatively smoothly, and reference image connections maintain natural, unified style. The overall texture approaches actual footage quality, though motion stability has room for improvement.
Audio Generation Leadership
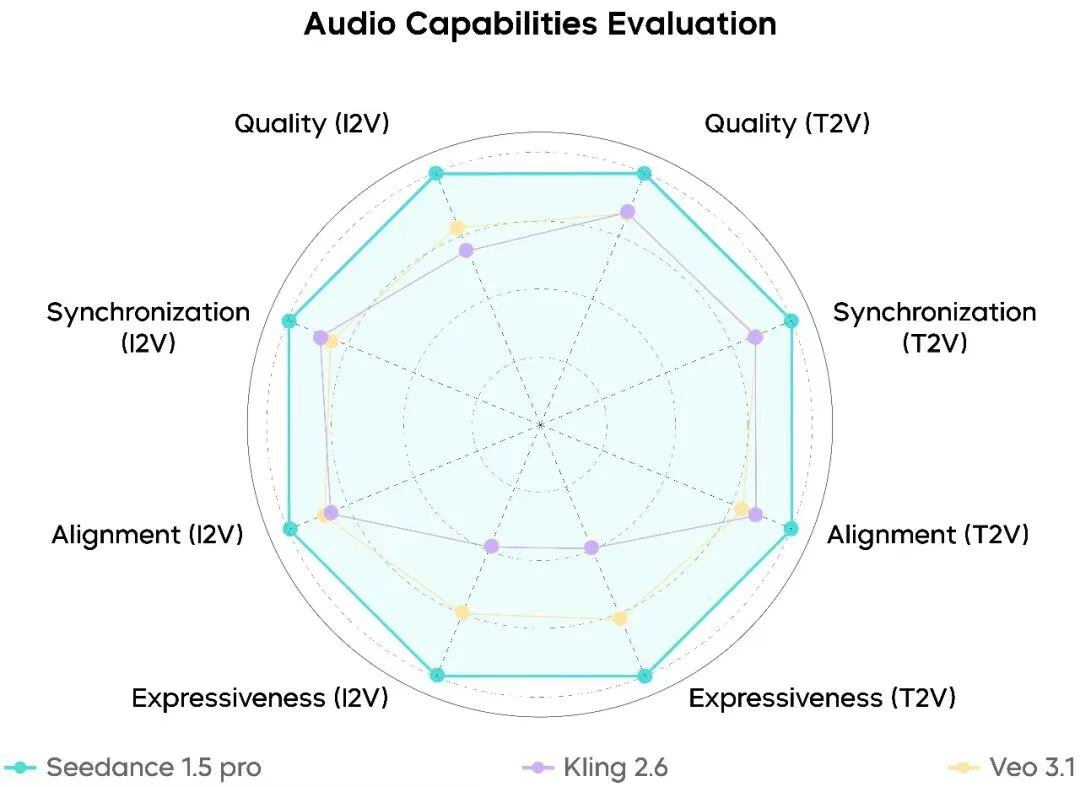
Seedance 1.5 Pro ranks at industry's top tier here, performing stably across audio instruction following, audio-video sync, and audio quality dimensions. It generates matching voices and specified sound effects with relative accuracy, showing particularly high completeness and pronunciation clarity in Mandarin dialogue scenarios with various dialect instructions.
Generated voices sound natural with minimal robotic qualities. Sound effects and spatial reverb approach reality, with significantly reduced audio-video misalignment. While multi-character alternating dialogue and singing scenarios need improvement, it's already partially applicable to Mandarin and dialect-driven short dramas, stage performances, and cinematic narrative scenarios.
You can try it yourself on JiMeng AI and Doubao.
Current Limitations and Future Direction
The model still needs work in physical stability for highly difficult movements, multi-character dialogue, and singing scenarios. The development team plans to focus on longer-duration narrative generation, more real-time edge experiences, and enhanced understanding of physical world rules and multimodal perception capabilities.
Their stated goal: making Seedance more vivid, efficient, and user-aware—helping creators break sensory boundaries and realize audio-visual creativity. Based on current capabilities, they're making solid progress toward that vision.
Impressed by AI video generation but don't have time to master complex tools? Try NemoVideo—drop your raw footage or ideas, and let AI handle the editing workflow from captions to voiceovers in minutes.